Publishing Records¶
The following will outline specifics for Publishing a Record Group, with more general information about running Jobs here.
How does Publishing work in Combine?¶
As a tool for aggregating metadata, Combine must also have the ability to serve or distribute aggregated Records again. This is done by “publishing” in Combine, which happens at the Job level.
When a Job is published, a user may a Publish Set Identifier (publish_set_id) that is used to aggregate and group published Records. For example, in the built-in OAI-PMH server, that Publish Set Identifier becomes the OAI set ID, or for exported flat XML files, the publish_set_id is used to create a folder hierarchy. Multiple Jobs can publish under the same Publish Set ID, allowing for grouping of materials when publishing.
Users may also select to publish a Job without a Publish Set Identifier, in which case the Records are still published, but will not aggregate under a particular publish set. In the outgoing OAI-PMH server, for example, the Records would not be a part of an OAI set (which is consistent and allowed in the standard).
On the back-end, publishing a Job adds a flag to Job that indicates it is published, with an optional publish_set_id. Unpublishing removes these flags, but maintains the Job and its Records.
Currently, the the following methods are avaialable for publishing Records from Combine:
Additionally, Combine supports the creation of “Published Subsets”. Published Subsets, true to their namesake, are user defined subsets of all published Records. You can read more about what those are, and creating them, here:
Publishing a Job¶
Publishing a Job can be initated one of two ways: from the Record Group’s list of Jobs which contains a column called “Publishing”:

Column in Jobs table for publishing a Job
Or the “Publish” tab from a Job’s details page. Both point a user to the same screen, which shows the current publish status for a Job.
If a Job is unpublished, a user is presented with a field to assign a Publish Set ID and publish a Job:

Screenshot to publish a Job
Also present, is the option of including this Publish Set ID in a pre-existing Published Subset. You can read more about those here.
If a Job is already published, a user is presented with information about the publish status, and the ability to unpublish:
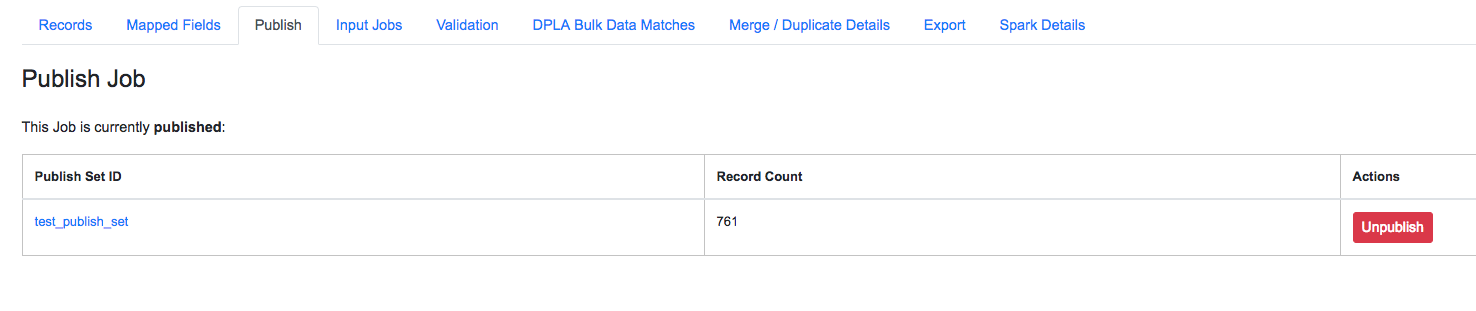
Screenshot of a published Job, with option to unpublish
Both publishing and unpublishing will run a background task.
Note: When selecting a Publish Set ID, consider that when the Records are later harvested from Combine, this Publish Set ID – at that point, an OAI set ID – will prefix the Record Identifier to create the OAI identifier. This behavior is consistent with other OAI-PMH aggregators / servers like REPOX. It is good to consider what OAI sets these Records have been published under in the past (thereby effecting their identifiers), and/or special characters should probably be avoided.
Identifiers during metadata aggregation is a complex issue, and will not be addressed here, but it’s important to note that the Publish Set ID set during Publishing Records in Combine will have bearing on those considerations.
Viewing Publishing Records¶
All published Records can be viewed from the “Published” section in Combine, which can be navigated to from a consistent link at the top of the page.
The “Published Sets” section in the upper-left show all published Jobs:
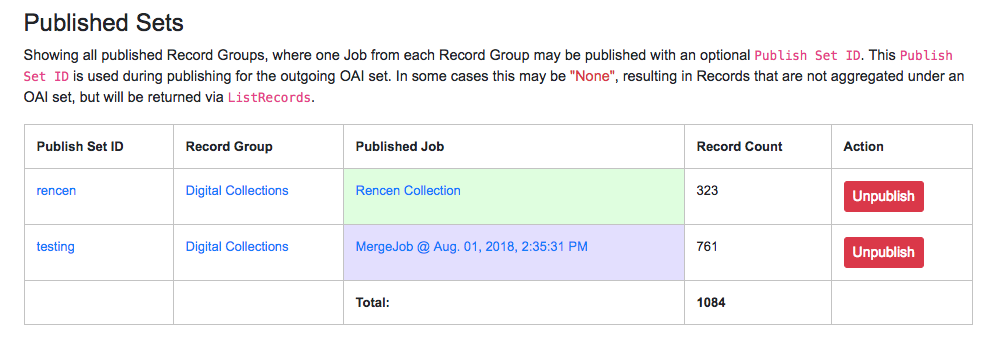
Published Jobs
As can be seen here, two Jobs are published, both from the same Record Group, but with different Publish Set IDs.
To the right, is an area called “Analysis” that allows for running an Analysis Job over all published records. While this would be possible from a manually started Analysis Job, carefully selecting all Publish Jobs throughout Combine, this is a convenience option to begin an Analysis Jobs with all published Records as input.
Below these two sections is a table of all published Records. Similar to tables of Records from a Job, this table also contains some unique columns specific to Published Records:
Outgoing OAI Set- the OAI set, aka the Publish Set ID, that the Record belongs toHarvested OAI Set- the OAI set that the Record was harvested under (empty if not harvested via OAI-PMH)Unique Record ID- whether or not the Record ID (record_id) is unique among all Published Records
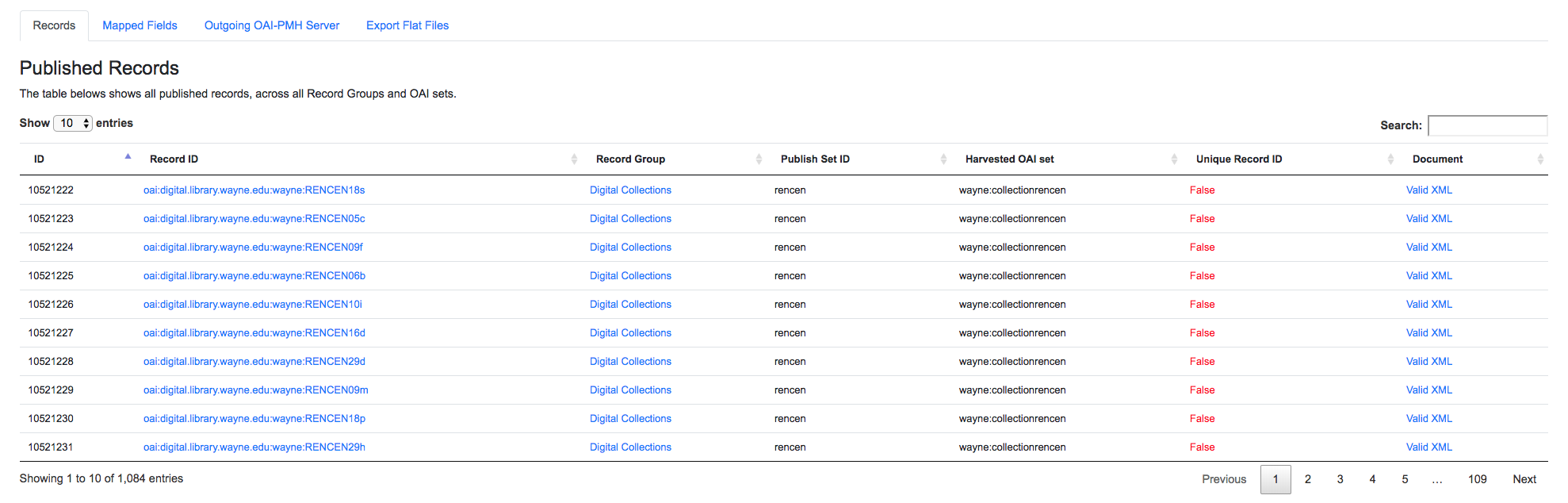
Table showing all Published Records
Next, there is a now hopefully familiar breakdown of mapped fields, but this time, for all published Records.
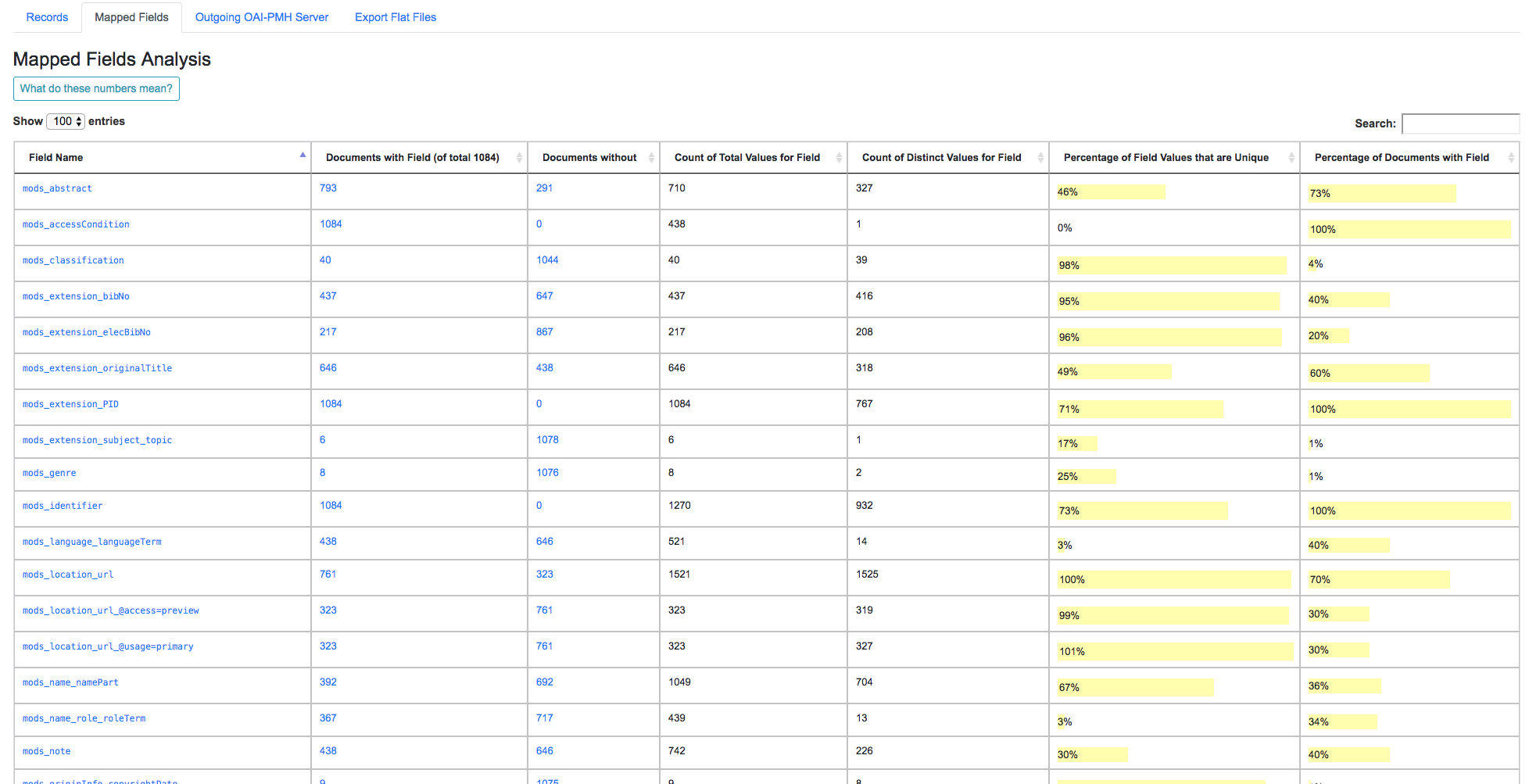
Screenshot of Mapped Fields across ALL published Records
While helpful in the Job setting, this breakdown can be particularly helpful for analyzing the distribution of metadata across Records that are slated for Publishing.
For example: determining if all records have an access URL. Once the mapped field has been identified as where this information should be – in this case mods_location_url_@usage=primary – we can search for this field and confirm that 100% of Records have a value for that mapped field.

Confirm important field exists in published Records
More on this in Analyzing Indexed Fields Breakdown.
OAI-PMH Server¶
Combine comes with a built-in OAI-PMH server that serves records directly from the MySQL database via the OAI-PMH protocol. This can be found under the “Outgoing OAI-PMH Server” tab:
Simple set of links that expose some of Combine’s built-in OAI-PMH server routes
Export Flat Files¶
Another way to “publish” or distribute Records from Combine is by exporting flat files of Record XML documents as an archive file. This can be done by clicking the “Export” tab and then “Export Documents”. Read more about exporting here.
Publish Set IDs will be used to organzize the exported XML files in the resulting archive file. For example, if a single Job was published under the Publish ID foo, and two Jobs were published under the Publish ID bar, and the user specified 100 Record per file, the resulting export structure would look similar to this:

Publish IDs as folder structured in exported Published Records
Published Subsets¶
Published Subsets are user defined subsets of all currently published Records and Jobs in Combine. They are created by selecting a combination of:
- Publish Set Identifiers to include in the subset
- all published Jobs without a Publish Set Identifier
- Organizations, Record Groups, and Jobs where all published Jobs are included
As Combine strives to be a single point of interaction for metadata harvesting, transformation, and publishing, it is expected that users may desire to expose only certain subsets of published records to downstream, non-Combine users. Published Subsets allow for this.
For example, imagine a single instance of Combine that is used to harvest, transform, QA, and publish metadata in support of a DPLA service hub. It may be convenient to also use this instance of Combine in support of a digital collection state portal. While there may be overlap in what Records and Jobs are published to both DPLA and the state portal, there may be some metadata records that should only propagate to one, but not the other.
By default, the built-in OAI-PMH server, and flat file exports, expose all published Records in Combine. For many use cases, this might be perfectly acceptable. Or, it may be such that careful use of Publish Set Identifiers – which translate directly to OAI sets – may be sufficient for managing that downstream consumers only harvest apporpriate records.
If, however, this is not the case, and more granular control is need, Published Subsets may be a good option for selecting subsets of published Records, which are then exposed through their own unique OAI-PMH endpoint, or flat file exports. In this scenario, the records bound for DPLA might be available through the subset dpla and the OAI endpoint /oai/subset/dpla, while the records bound for the state portal could be available in the subset start_portal and available for OAI harvest from /oai/subset/state_portal.
All Published Subsets also allow the normal exporting of Records (flat XML, S3, etc.).
Viewing Published Subsets¶
Published Subset can be found at the bottom of the Published screen:

Viewing all Published Subsets (none selected)
Clicking the View button, will redirect to the familiar Published screen, with this particular Published Subset selected. This is indicated by a notification at the top:

Notification of viewing Published Subset
and in the Published Subset table at the bottom:

Published Subsets table, while viewing one
When viewing a paricular subset, the tabs “Records” and “Mapped Fields” show only Records that belong to that particular subset. Clicking the “Outgoing OAI-PMH Server” tab will show the familiar OAI-PMH links, but now navigating to an OAI endpoint that contains only these records (e.g. /oai/subset/dpla as opposed to the default /oai).
Note: The Published Set state_portal shares the Published Set Identifier set2 with dpla, demonstrating that overlap between Published Subsets is allowed. And notes True that Records not belonging to a Publish Set are included as well.
Creating a Published Subset¶
To create a Published Subset, click “Create Published Subset” at the bottom, where you will be presented with a screen similar to this:
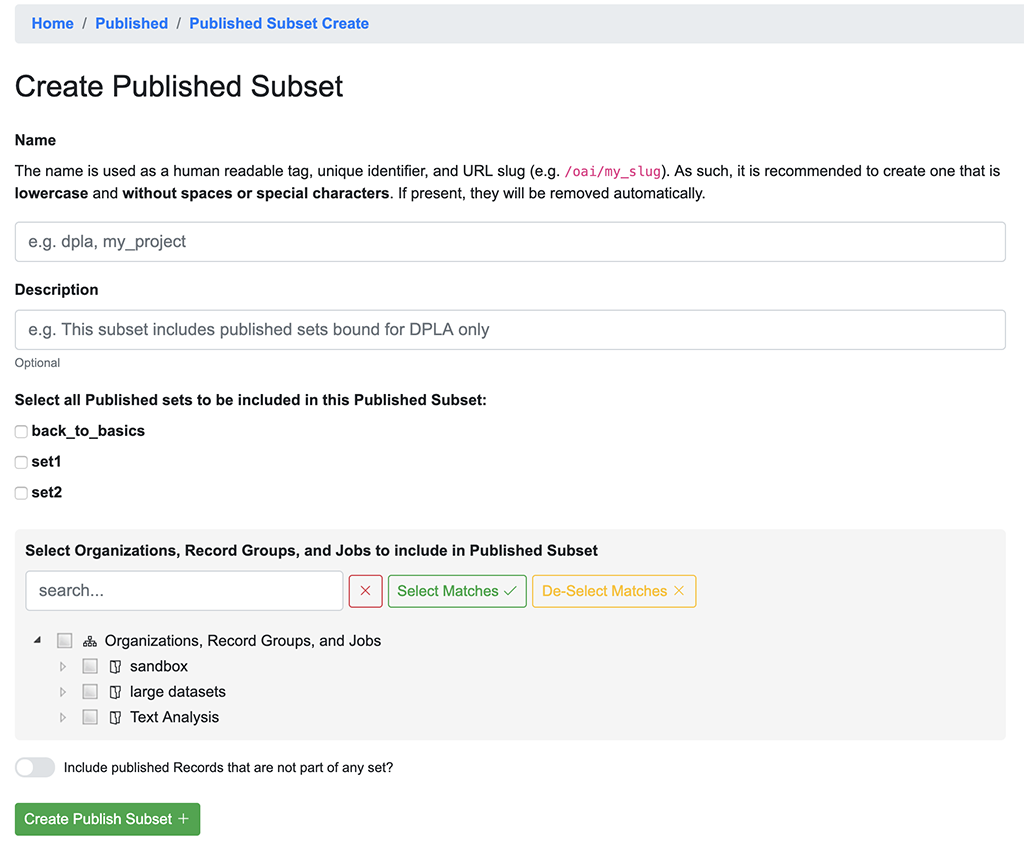
Creating a Published Subset
- Name
- A unique identifier for this Published Subset, that will also be used in URL patterns (e.g. the created OAI endpoint). This should be lowercase and without special characters or spaces.
- Description
- Human readable description of this Published Subset.
- Select Published Sets
- This is where published sets are selected to include in this Published Subset. All or none may be included.
- Select Organizations, Record Groups, and Jobs
- Select Organizations, Record Groups, and Jobs to include in Published Subset. Selected Organizations and Record Groups will include all published Jobs that fall underneath. In the instance where only select Jobs from a Record Group are selected, only those Jobs will be included, not the entire Record Group.
- Note: This is particularly helpful if a user wants to add an entire Organization or Record Group to a subset, confident that all Jobs created or deleted, published or unpublished, will collect under this Published Subset.
- Include Records without Publish Set Identifier
- This toggle will include Jobs/Records that have not been given a Publish Set Identifier in this Published Subset.